
Beyond Vibe Coding
Introducing ***plain, the Language of Spec-Driven Development

Sometimes, coding is the most efficient way of specifying functionality. If we look at the following algorithm, it is much easier to express it in code:
def func_A(n):
return 2 if n == 1 else n * func_A(n // 3 + 1)than in words:
Write a function that multiplies n by smaller and smaller integers obtained by integer-dividing by 3 and adding 1 each time, until it reaches 1, at which point it uses 2 instead of 1 in the multiplication.When precision and control are essential, code gives the developer ultimate power.
But such power is rarely needed. Outside of the domain of non-standard algorithms and mathematical expressions, specifying by coding is cumbersome and inefficient in describing the desired functionality. For example, the code below:
def fetch(limit=100):
headers = {"Authorization": f"Bearer {API_KEY}"}
cursor = None
users = []
while True:
params = {"limit": limit}
if cursor:
params["cursor"] = cursor
r = requests.get(f"{BASE_URL}/v1/users",
headers=headers, params=params)
r.raise_for_status()
payload = r.json()
users.extend(payload.get("data", []))
cursor = payload.get("next_cursor")
if not cursor:
break
return useris much harder for a human to write and understand than this natural language specification:
Fetch the list of users from the API.Even if we want to be more specific in guiding the implementation, it is more efficient to specify the preferred approach (e.g., implement paging using cursors) than to code it ourselves.
Only in computer programming have we turned to a fully artificial language to express intent. Even in mathematics, most of a paper or proof is written not in formulas but in words. Laws, too, are composed in natural language, and attempts to formalize them have succeeded only in the simplest of cases. No programming language approaches the expressiveness of natural language or the way it aligns with how the human mind works.
No programming language approaches the expressiveness of natural language or the way it aligns with how the human mind works.
Inefficiency is not the only issue with specifying software functionality through code. To increase productivity and improve maintainability, developers naturally strive to reuse code and share logic. However, when reuse happens at the level of shared code, it leads to functionality blending, that is, it becomes difficult to isolate in code where one functionality ends and another begins. Because multiple functionalities are intertwined, modifying the implementation code can lead to unintended side effects — software bugs in other functionalities that share the same code paths. Cross-cutting concerns (e.g., logging, validation, error handling) further complicate the codebase, making software maintenance increasingly difficult.
While coding, developers also clarify in their mind the intent behind their decisions. But once the code is written and the mental model behind the code fades, recovering that intent can be difficult — even when the code is well-documented with semantic identifiers and comments. This becomes especially challenging when functionality is distributed across multiple locations in the codebase. A developer looking to fix a bug or implement a new functionality must first reconstruct the original intent to avoid introducing new issues. The loss of intent is a major reason why developers dislike maintaining legacy systems and why it takes so long to become productive in a new codebase.
Vibe Coding: Fix One Thing, Break Ten Others
Vibe coding1 is the practice of building software by chatting with the AI — nudging features, fixing bugs, and shaping the app — instead of hand-coding everything yourself. The value of vibe coding over classical coding is that it leverages the full expressivity of the natural language for specifying intended functionality. In most cases, this is much more efficient than specifying by coding.
Vibe coding operates in a task-oriented2 mode: the developer describes a task in natural language, and the AI generates code to implement it. Once the code has been generated, the natural language instructions become obsolete, leaving the code as the sole source of truth for how the software behaves.
If it turns out that an earlier task was incorrectly specified or implemented, the developer must either attempt to correct it by submitting new tasks or fix the issue directly in the code. If these approaches fail or take too long, the only remaining option may be to revert to a previous working version of the code, losing all the work made in subsequent steps.

Fixing issues by submitting new tasks often feels like playing whack-a-mole — resolve one bug, and two more appear3. The root problem is that vibe coding lacks a reliable way to rescind or alter the result of a previous task, short of rolling back to an earlier working version. Even if you instruct the AI to “undo” a change, there’s no guarantee it will fully comply. Functionality blending makes this even worse: once subsequent instructions layer new logic on top of the old, the code becomes so intertwined that reversing specific changes without collateral damage is nearly impossible.
Compounding the problem is that vibe coding lacks tools to detect and resolve ambiguities in specifications or conflicts between specifications issued across different tasks. This becomes especially problematic in team settings. Vibe coding provides no support for cooperation between developers at the specification level, leaving them instead to rely on code reviews to resolve differences and conflicts in understanding the specifications.
If the developer must resort to code to fix the issue, most of the advantages of vibe coding disappear. First, the developer must be versed in the implementation technology. Second, to fix the issue without introducing new bugs the developer must understand the code base. Third, instead of doing the most valuable part of coding (implementing new functionality), the developer is left with the most tedious and least enjoyable task — fixing issues.
Spec-Driven Development: The Mature Way Forward
Vibe coding brings the efficiency of natural language to programming, but for control and precision, modular reuse, teamwork and clarity, developers still need to turn to code. To move beyond vibe coding and unlock the full potential of using natural language to specify software, developers must be able to fix any issue entirely within the specifications — without ever touching the underlying code. Spec-driven development delivers on this promise by making a key shift: instead of treating code as the source of truth — as is the case with task-oriented vibe coding — spec-driven development uses specifications as the source of truth for the software’s functionality4.
This represents a major paradigm shift in programming, and understandably, developers are very skeptical about whether it’s even possible. The two objections most frequently raised against using specifications as the source of truth are the inherent ambiguity of natural language and functionality flickering5.
Source code written in a programming language does not exhibit ambiguity; there is only one valid interpretation of a C program or a Python script. By contrast, natural language is inherently ambiguous, and there is always a possibility that someone will misinterpret a statement. But in the vast majority of cases, this is not a problem — humans understand each other quite well.
The solution to the problem of ambiguity in natural language is well established: when a reasonable person might perceive ambiguity, the specification should be strengthened to eliminate it. Humans have refined this for at least 4,000 years6 in codified legal systems — through interpretation and precedent — where it’s proven durable and effective.
In spec-driven development, ambiguity first needs to be detected — either through automated detection or by a developer noticing that the software is not behaving as intended. Once identified, the developer can respond in one of two ways: (i) by refining the specification to eliminate the ambiguity, or (ii) adding a special case to define how the software should handle the particular situation.
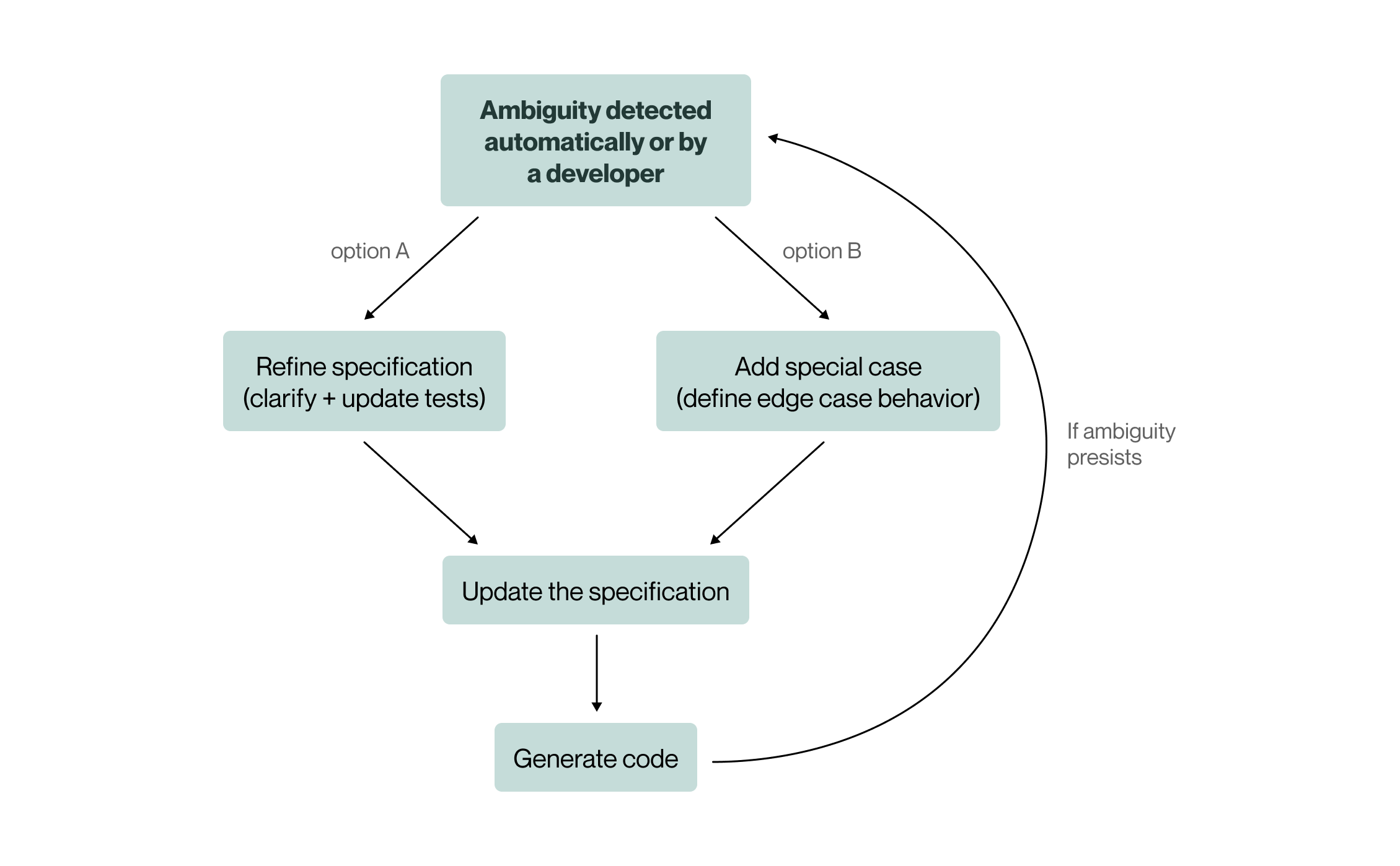
The other argument against using specifications as the source of truth is functionality flickering, that is, an undesirable phenomenon in spec-driven software development where underspecification makes generated functionality vary between code generations. For example, if the color of a button is left undefined, one generation might produce a green button and the next a red one, confusing users and undermining their trust.
Functionality flickering is not a new phenomenon — it only became noticeable with the rise of AI-powered code generation, which can produce multiple implementations from the same specification quickly and at low cost. The same effect appears with human developers: when given identical specifications, the end result will also look and feel very different. This variation arises because developers make many micro-decisions during coding, each influencing the functionality of the software. For example, if the color of a button is unspecified, one developer may choose yellow while another selects blue. From a functionality standpoint, the color is irrelevant (and therefore left unspecified). From a user’s perspective, however, the inconsistency can be confusing — for instance, if one version of the software presents an orange button while another shows a gray one7.
To prevent functionality flickering, it is necessary to detect and record the micro-decisions made during coding that affect software behavior. In subsequent code generations, these records must be reconsidered to ensure the software retains exactly the same functionality as before.
Introducing ***plain, the Language of Spec-Driven Development
To realize the vision of spec-driven development, *codeplain today announces ***plain — a specification language that combines the efficiency of natural language with the control and precision of code. Built on Markdown, ***plain introduces new syntax that allows developers to express intent at any level of detail. This enables ***plain renderer to consistently and reliably generate software code from specifications.

The core idea behind ***plain is that software can be specified as a union of (partially) overlapping functionalities, from which implementation code can always be generated from scratch. Developers are free to describe functionality in any way they choose, including using the full expressiveness of natural language, with the only limitation being that the description must be text-based. The functionalities can share concepts, thus enabling the building of complex functionality out of simpler functionalities.
In ***plain, specifications for overlapping functionalities must not contradict one another. If a conflict is found, it must be resolved by rewriting the specifications. Additionally, any complex functionality must be decomposed into simpler, more manageable parts. If decomposition is not possible, concrete examples must be provided in the form of acceptance tests8. These examples help the ***plain renderer generate code in small, testable increments, ensuring consistent and reliable output.
To ensure that the implementation code fully conforms to the specification, unit tests and conformance tests9 can be automatically generated from the same source specification. The specification can be further strengthened by additional acceptance tests written by the developer to disambiguate unclear specifications or address bugs in the implementation. Before new functionality is rendered or existing functionality is re-rendered, all tests must pass. Once functionality is implemented, the tests serve to detect regressions and verify that the implementation conforms to the specification.
Because ***plain specification is a collection of text files, all the powerful tooling that has evolved for coding can be fully reused. ***plain specification:
Can be version controlled, enabling traceability and compliance
Can use templates, enabling modular reuse of specifications
Can be developed with AI-powered tools (e.g., Cursor)
Enables concurrent teamwork with seamless merging
***plain also makes it easier for teams to share effective practices and successful patterns, much like they would with classical code. By expressing specifications in a standardized, structured form, developers can learn from one another’s approaches — for example, how to write clearer specifications or organize them into a coherent whole — without depending on informal, ad-hoc knowledge transfer.
The structure of the ***plain specification language — especially its syntax — is still under active development. Its first official release is planned for fall 2025, guided by the ***plain language working group.
We are now opening the group to a limited number of new members. The group’s initial members include Dusan Omercevic, founder of *codeplain, and Johan Rosenkilde, creator of SpecLang10 and a former member of the original GitHub Copilot team.
If you’re interested in contributing, please reach out to us at lang@plainlang.org.
The development of ***plain is made possible through the support of *codeplain, an AI-powered code generation service that produces production-ready software from specifications written in the ***plain language. For more information, visit www.codeplain.ai or email info@codeplain.ai.
Hat tip to John Berryman for framing the move from vibe coding to spec-driven development as ‘the mature way forward’ (personal communication).
Please note that we are intentionally inconsistent with colors in this paragraph to illustrate the flickering phenomenon being described.
Acceptance tests verify requirements and validate user needs.
Conformance tests verify correctness against specifications.
SpecLang was an experimental project at GitHub Next, an early attempt at spec-driven development that explored using structured natural language to generate code. See https://githubnext.com/projects/speclang/ for more information about the SpecLang project.